Every second Tuesday of the month, Microsoft drops its security bulletin. Your inbox fills with alerts. Your security scanner lights up like a Christmas tree. And somewhere in your organization, a manager asks the question that makes every security engineer’s eye twitch: “So we’ll have all these patched by end of the month, right?”
No. We will not.
Not because the team is lazy. Not because the tools are bad. Because the distance between a CVSS score and a safe production deployment is longer than anyone outside the security team wants to admit — and in regulated, validated, or complex enterprise environments, that distance is measured in weeks or months, not days.
This article is about what vulnerability management actually looks like in enterprise reality: the metrics that matter, the constraints most frameworks ignore, and how to build a program that’s honest about the tradeoffs rather than pretending they don’t exist.
CVSS Scores Are Not Risk Scores — Stop Treating Them Like They Are
The Common Vulnerability Scoring System (CVSS) is a severity scoring framework, not a risk framework. This distinction is fundamental and widely ignored, with real operational consequences.
A CVSS score measures two things: the inherent characteristics of the vulnerability (attack vector, complexity, privileges required, user interaction) and the potential impact if exploited (confidentiality, integrity, availability impact). What it explicitly does not measure is the risk to your specific environment.
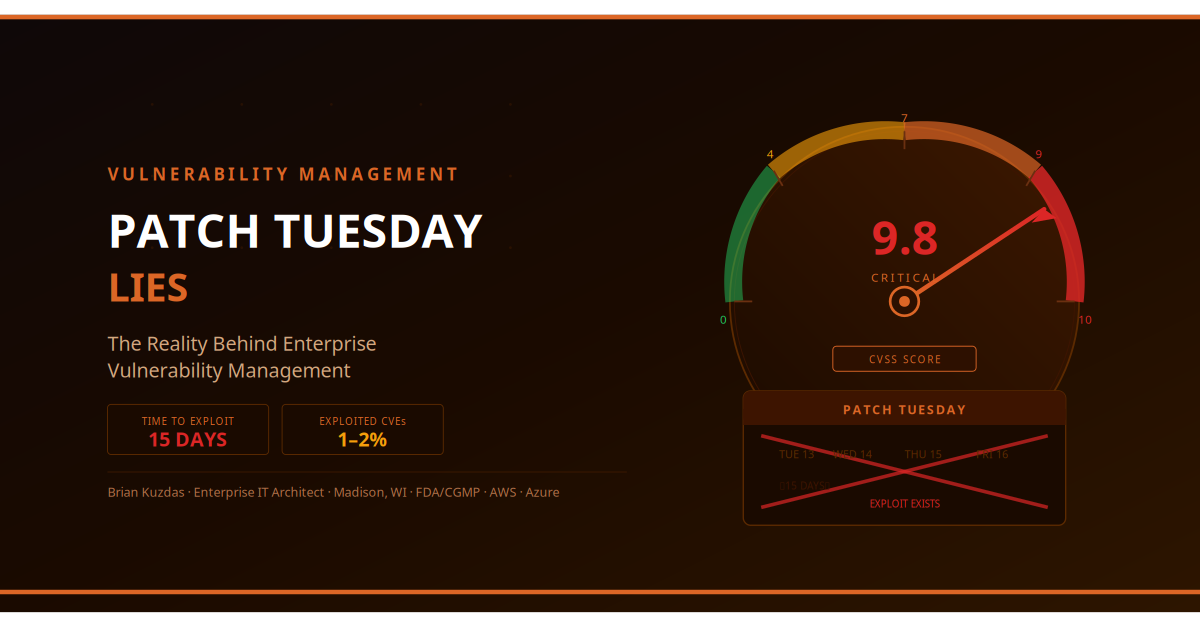
A CVSS 9.8 critical vulnerability in Apache software you do not run is a zero-risk event for your organization. A CVSS 6.5 medium vulnerability in a legacy application that processes PHI, is internet-exposed, has no compensating controls, and has a public proof-of-concept exploit is potentially your highest-priority remediation item this month.
The NIST National Vulnerability Database (NVD) itself acknowledges this: CVSS scores are environmental scores that should be customized with temporal and environmental metrics for each organization. Almost nobody does this. Instead, organizations run automated scanners, sort by CVSS score descending, and tell their teams to work from the top of the list.
This produces the wrong work. Organizations treating CVSS as risk routinely:
- Prioritize patching development servers that aren’t accessible externally over production systems with internet exposure
- Spend weeks remediating theoretical vulnerabilities in software versions they’re not actually running
- Miss genuinely dangerous medium-severity CVEs because they’re buried below hundreds of high/critical scores on unimportant systems
The CISA Known Exploited Vulnerabilities (KEV) catalog is a far better starting point for prioritization than CVSS. As of 2024, CISA’s KEV catalog contains over 1,000 CVEs with confirmed exploitation in the wild. The overlap between the KEV catalog and your environment is a better risk signal than any CVSS score.
Qualys TruRisk research found that only about 1-2% of vulnerabilities are ever actually exploited in the wild. You’re spending enormous resources remediating 98% of your vulnerability findings that pose no realistic threat while the 2% that matter may be buried in the noise.
The Gap Between Disclosure and Exploitation
The window between when a vulnerability is publicly disclosed and when attackers have a working weaponized exploit is narrowing dangerously.
Historically, the conventional wisdom was that organizations had 30-90 days between disclosure and widespread exploitation — enough time to patch on a monthly cycle. That assumption is now dangerously outdated.
Research from Qualys and multiple threat intelligence firms shows the average time from NVD publication to a working weaponized exploit is now approximately 15 days for high-severity vulnerabilities. For vulnerabilities with public proof-of-concept code available at disclosure, the timeline is even shorter — exploit code is frequently available within hours.
The Verizon Data Breach Investigations Report (DBIR) 2023 is blunt about this: exploitation of vulnerabilities as the initial access vector increased significantly year-over-year, with attackers demonstrably scanning for vulnerable systems within hours of CVE publication. Your 30-day patch SLA was designed for an era that no longer exists.
The practical implication: for the small subset of vulnerabilities in your environment that are externally exploitable, on systems running the affected software version, without compensating controls — your patch timeline must be measured in days, not the traditional monthly cycle. Compensating controls (network segmentation, WAF rules, temporary service isolation) buy time. They are not a substitute for patching.
The race between the attacker and the defender is asymmetric: the attacker only needs to find one unpatched system. You need to find and remediate all of them.
Patching in FDA/CGMP Validated Environments: The Constraint Nobody Talks About
Here is the conversation that doesn’t happen in most vulnerability management frameworks, but dominates the operational reality of pharmaceutical manufacturing, medical device companies, and FDA-regulated clinical research organizations:
“We’ve identified a critical patch. Can we deploy it this week?"
"That system is a validated GxP system. We need to do an impact assessment, determine if the patch affects validated functionality, document the assessment, update our validation documentation if needed, and potentially re-execute affected test scripts. Depending on the results, we’re looking at 4-8 weeks minimum."
"The CVE is rated 9.8."
"I understand. We’re also under FDA inspection in three weeks and we cannot introduce unvalidated changes to GxP systems pre-inspection. We’ll expedite the impact assessment and implement compensating controls.”
This conversation is real, it happens constantly, and it represents a genuine tension that generic vulnerability management guidance completely ignores.
Under 21 CFR Part 11 and broader FDA GxP requirements (21 CFR Part 820 for devices, 21 CFR Part 211 for pharmaceutical manufacturing), software changes to validated systems — including security patches — must be evaluated for impact on the validated state. A patch that modifies application behavior, changes interface elements, or affects data integrity mechanisms may require partial or full revalidation.
The FDA does not grant exemptions for security patches. In fact, FDA guidance on computer software validation explicitly addresses patches and updates: they are changes that must be evaluated under the organization’s change control process.
The practical approach for regulated environments:
- Classify systems: GxP critical, GxP adjacent, non-GxP. Patch timelines differ for each tier.
- Pre-populate impact assessment templates: When a new CVE drops, the 70% of the impact assessment that’s always the same (system description, validation status, data flow) should already be filled out.
- Establish emergency patch procedures: For truly critical patches on GxP systems, have a pre-approved emergency change procedure that compresses the timeline without eliminating the required steps.
- Compensating controls are not optional: For any validated system that cannot be patched on the standard enterprise timeline, mandatory compensating controls (network isolation, enhanced monitoring, access restriction) must be implemented and documented.
The FDA has been increasingly specific about cybersecurity expectations for validated systems. The September 2023 FDA guidance on cybersecurity in medical devices explicitly requires a documented patch management process that balances security requirements with validation requirements. Ignoring either side of that balance is a compliance failure.
The Patches That Break Things: A Reality Check
Every enterprise security team has war stories. The patch that killed the production ERP. The update that broke authentication for 4,000 employees. The “low-risk” OS patch that introduced an incompatibility with a line-of-business application that hadn’t been touched in seven years.
These aren’t hypothetical risks. Microsoft’s Patch Tuesday has a documented history of patches requiring rapid out-of-band fixes:
- KB5012643 (May 2022): Broke .NET applications on Windows Server
- KB5028185 (July 2023): Caused authentication failures with Kerberos and Active Directory
- Dozens of printer driver, LSASS, and DNS client patches over the years that required rapid rollback
The organizational response to “patches break things” is often to slow patching down to reduce risk. This is a rational but dangerous choice — it trades patch-related outage risk for breach risk. The correct response is to build the infrastructure that lets you patch quickly and safely:
Staging environments that mirror production. Not “a test server” — actual representative environments with the same OS versions, same application stacks, same middleware configurations. A patch that breaks staging should not reach production.
Automated rollback capability. For Windows environments, Windows Server Update Services (WSUS) rollback capability. For cloud environments, snapshots and automated rollback pipelines. For containerized workloads, the rollback is already built in — use it.
Patch ring deployment. Deploy to a canary group (5-10% of systems, preferably non-critical) first. Hold 48-72 hours. If no critical issues, expand to the next ring. Full deployment should be measured in days, not the single “everyone gets it at once” approach that turns every Patch Tuesday into a roulette wheel.
Application compatibility testing. For enterprise applications, maintain an automated regression test suite that can be executed within 24 hours of a patch deployment. Manual testing of hundreds of applications is what makes 30-day SLAs a fiction.
Why Your 30-Day Patch SLA Is a Work of Fiction
Let’s walk through the organizational reality of remediating a critical patch in a typical enterprise:
Week 1: Vulnerability disclosed Tuesday. Scanners detect affected systems by Thursday. Ticket created. Change request submitted to change advisory board (CAB). Next CAB meeting: the following Tuesday.
Week 2: CAB reviews change. Requests additional information: impact assessment, rollback plan, testing confirmation. Scheduled for the following week’s CAB.
Week 3: CAB approves change with conditions: must be deployed during Saturday maintenance window, requires 2-hour testing window, backup must be confirmed pre-deployment. Deployment window is 11 days away.
Week 4: Deployment begins Saturday night. Patch causes unexpected behavior with Line-of-Business Application X. Roll back at 3 AM. Restart change process.
Week 5: Vendor patch for the patch application compatibility issue. Resubmit to CAB.
This is not a dysfunctional organization. This is the normal organizational bureaucracy of enterprise change management, and it is incompatible with a 30-day SLA for anything non-trivial.
The CISA Known Exploited Vulnerabilities catalog tells the real story: the average remediation time for KEV catalog items — the most critical, confirmed-exploited vulnerabilities — is over 30 days even at organizations that are actively trying to hit that target.
A realistic vulnerability management program doesn’t have one SLA. It has a tiered SLA structure:
| Tier | Definition | Target Timeline |
|---|---|---|
| Critical/Exploited | KEV catalog, internet-facing, no compensating controls | 7 days (with compensating controls applied within 24 hours) |
| High | CVSS 7.0+, internet-facing or high-value asset | 30 days |
| Medium | CVSS 4.0-6.9, internal systems | 90 days |
| Low | CVSS < 4.0, low-value assets | 180 days or risk-accepted |
| GxP Validated | Any severity, validated system | Per validation impact assessment (minimum 30 days, max defined by risk) |
The SLA structure isn’t an excuse — it’s an honest representation of organizational capability that allows for intelligent exception management.
What a Real Vulnerability Management Program Looks Like
Most vulnerability management programs are built backwards: they start with a scanner, create a list of findings, and work from the top of the CVSS-sorted list. This produces a program that is always behind, always reactive, and never able to demonstrate meaningful risk reduction.
A mature vulnerability management program is built from the risk side, not the scanner side:
1. Comprehensive Asset Inventory (Foundation) You cannot patch what you don’t know about. An asset inventory that is more than 90 days stale is not a vulnerability management foundation — it’s a liability. Asset discovery must be continuous, not periodic. CMDB accuracy is not an IT hygiene issue; it is a security prerequisite.
2. Continuous Scanning with Context Scanners provide vulnerability findings. Context transforms findings into risk. Context includes: is the system internet-facing? Does it store sensitive data? Is it in scope for regulatory compliance? Does it have compensating controls already applied? A scanner finding without this context is just a number.
3. Risk-Based Prioritization Combine CVSS base score with: exposure (internet-facing vs. internal), exploitability (KEV catalog, active exploitation in the wild, public PoC availability), compensating controls in place, and asset criticality (business value, data sensitivity, regulatory scope). The output is an asset-specific risk score that reflects your environment, not abstract severity.
4. SLA Tiers with Exception Management Define realistic SLAs by tier (as above). Build a formal exception process for systems that cannot meet SLA — documented risk acceptance, compensating controls requirement, re-review timeline. Exceptions without controls are audit findings waiting to happen.
5. Metrics That Tell the Truth Track: number of vulnerabilities by tier and their age, percentage meeting SLA by tier, mean time to remediate (MTTR) by severity, number of active exceptions, and exception-to-remediation conversion rate. Present these to leadership monthly. Metrics that show only compliance (green) and never show risk (amber/red) are metrics that nobody believes.
6. Program Maturity Roadmap Year 1: Establish baseline inventory, scanning coverage, and basic SLA structure. Year 2: Automate remediation workflow, build risk scoring, implement ring-based patching. Year 3: Predictive prioritization, threat-intelligence-integrated scoring, developer-facing vulnerability management for application security.
Verizon DBIR 2023 data consistently shows that the majority of breaches exploit known vulnerabilities for which patches were available. The gap is not the availability of fixes — it’s the organizational capability to apply them systematically at scale.
Bottom Line: What Mature Vulnerability Management Actually Requires
The organizations that do vulnerability management well aren’t the ones with the most expensive scanner — they’re the ones that have solved the organizational problem, not just the technology problem.
1. Separate severity from risk. CVSS tells you about the vulnerability. Risk scoring tells you about your environment. Build a scoring methodology that combines both.
2. Get on the KEV catalog. Subscribe to CISA KEV updates. Any KEV catalog item in your environment is an immediate priority, regardless of CVSS score.
3. Build honest SLA tiers. A single “30-day patch SLA” is theater. Tier your SLAs by actual risk, document the tiers, and measure against them transparently.
4. Create a validated system playbook. For every FDA/CGMP system in your environment, document the patch evaluation process before you need it. Pre-populated impact assessment templates cut evaluation time by 60-70%.
5. Invest in the patch infrastructure. Staging environments, automated rollback, ring deployment, and application compatibility testing are not overhead — they’re what make fast patching safe.
6. Measure and report risk reduction, not just remediation volume. Closing 500 low-risk findings while leaving 5 critical exploitable vulnerabilities open is a reporting success and a security failure.
The real story behind Patch Tuesday isn’t that patching is hard. It’s that vulnerability management is an organizational capability problem that technology alone cannot solve.
References and Further Reading
-
CISA Known Exploited Vulnerabilities (KEV) Catalog — https://www.cisa.gov/known-exploited-vulnerabilities-catalog
-
Verizon Data Breach Investigations Report 2023 — https://www.verizon.com/business/resources/reports/dbir/
-
NIST National Vulnerability Database (NVD) — https://nvd.nist.gov/
-
Qualys TruRisk Research: Prioritizing Vulnerability Remediation — https://www.qualys.com/research/
-
FDA Guidance on Cybersecurity in Medical Devices (September 2023) — https://www.fda.gov/regulatory-information/search-fda-guidance-documents/cybersecurity-medical-devices-quality-system-considerations-and-content-premarket-submissions
-
FDA 21 CFR Part 11: Electronic Records; Electronic Signatures — https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfcfr/CFRSearch.cfm?CFRPart=11
-
Gartner: Vulnerability Management Market Guide (current year) — https://www.gartner.com (subscription required)
-
NIST SP 800-40r4: Guide to Enterprise Patch Management Planning — https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r4.pdf
#VulnerabilityManagement #CyberSecurity #PatchManagement #CVSS #CISA #EnterpriseIT #CGMP #FDA #RiskManagement #InformationSecurity